Носители данных
До некоторой степени формализованное представление структур данных, которые являются носителями информации, с точки зрения их преобразования в RDF-представления
(примерное время чтения 6 минут)
Первичные деревья
Мы используем термин данные для обозначения информации, представленной в некотором конкретном виде пригодном для хранения, передачи и подработки. При этом допускаем, что в данных может и не содержаться пригодной для содержательной интерпретации информации.
Данные представляются в виде какой-то конкретной структуры. Здесь мы будем рассматривать только структуры в виде деревьев. При этом предполагаем, что и многие другие популярные структуры данных (в том числе популярные таблицы и списки) могут быть представлены в виде дерева.
Нами рассмотрена задача представления данных в независимом от контекста виде. Это предполагает, что при интерпретации данных и извлечении из них информации не требуется отдельно знать интерпретацию семантики данных. Один из способов такого представления данных реализует концепция RDF. Носителем RDF-данных (или RDF-представлений данных) также выступает структура в виде дерева, которое мы будем называть RDF-граф.
Таким образом, задача трансформации "обычных" данных в RDF-представление (мы также использовали термин "семантическое обогащение данных") сводится к преобразованию одного дерева в другое.
Производные представления
RDF-граф состоит из атомарных RDF-структур - триплетов. Триплеты к сущностям "привязывают" имена свойств, а к именам свойств "привязывают" значения свойств. В RDF-представлении "сущность" - это уникальный в рамках всего массива данных идентификатор. Значения свойств могут быть как просто строками, так и сущностями (структуру и пример сериализация в триплеты см. здесь). Соответственно сериализованные RDF-триплеты могут быть двух типов:
- "сущность" -> "имя свойства" -> "строковое значение"
- "сущность" -> "имя свойства" -> "ссылка на сущность"
В общем случае, ссылка в значении свойства, может указывать как на сущность описанную в другом исходном графе, так и на сущность описанную на нижестоящем уровне текущего фрагмента. Второй вариант фактически порождает фрактальную структуру получаемого RDF-представления.
Следовательно дерево c первичными данными должно быть таким, чтобы его структуру можно было интерпретировать аналогичным образом:
- либо как
"слой сущностей" -> "слой имен свойств" -> "слой значений свойств", - либо как
"слой сущностей" -> "слой имен свойств" -> ["слой сущностей" -> "слой имен свойств" -> ("слой значений свойств" | "слой сущностей")]
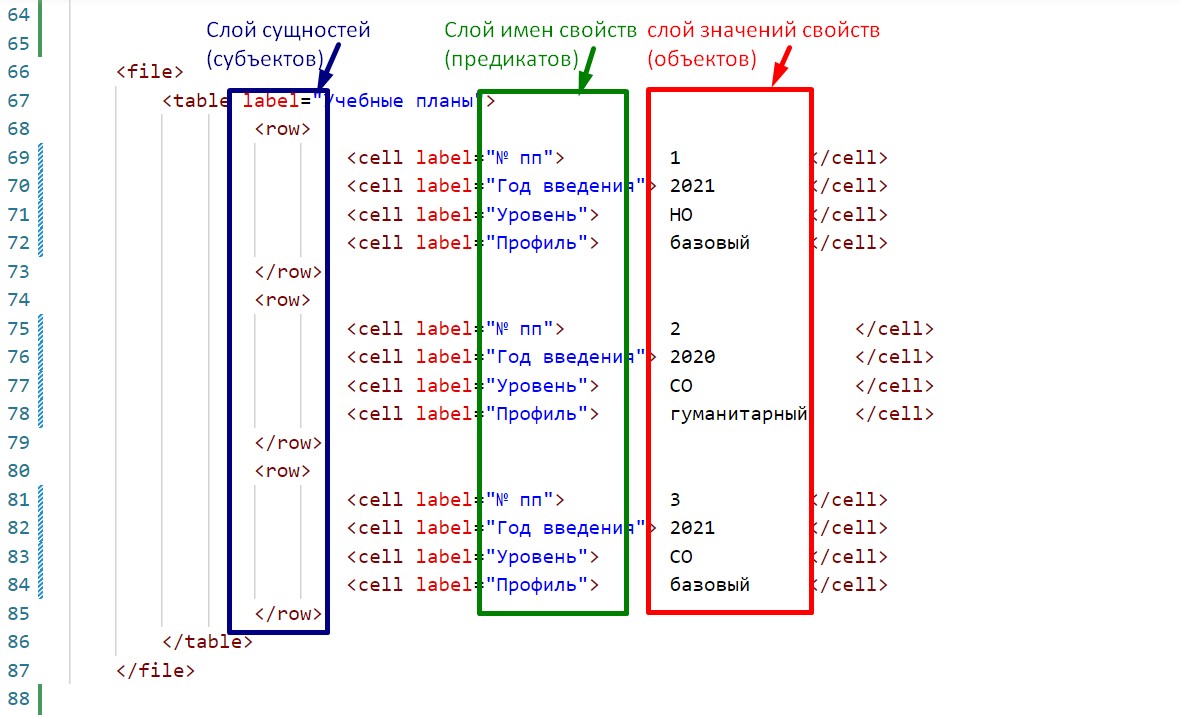 Рис. 1. Соответствие уровней иерархических данных структуре RDF-представления (триплету)
(для увеличения - кликните на картинку)
Рис. 1. Соответствие уровней иерархических данных структуре RDF-представления (триплету)
(для увеличения - кликните на картинку)
В практической реализации слои могут выделены с помощью инструкций на языке XQuery/XPath следующим образом:
- слой сущностей ("субъектов"):
./file/table/row - слой имен свойств ("предикатов"):
./file/table/row/cell/@label - слой значений свойств ("объектов"):
./file/table/row/cell/text()
Соответственно конкретный набор данных для конструирования триплета может быть выражен тройкой инструкций (запросов) на языке XQuery/XPath:
<./file/table/row[2]/cell[1]/text()> - < ./file/table/row[2]/cell[4]/@label > - "./file/table/row[2]/cell[4]/text()"
Здесь в качестве идентификатора сущности принято значение свойства с именем "№ пп". Таким образом, приведенная выше запись даст такой триплет:
<1> - <Профиль> - "гуманитарный"Интерпретация такого триплета может быть следующей: "Сущность с идентификатором <1> имеет признак "Профиль", значение которого равно "гуманитарный".
Так как значением свойства может быть ссылка (на самом деле глобальный идентификатор - URI) на некоторую сущность, то на каждом уровне, где такая ссылка (идентификатор) должна появляться, предполагается наличие информации для конструирования такого идентификатора или получения идентификатора по запросу из базы данных.
В рассмотренном примере про реестр учебных планов значение признака "Уровень" будет отображено в идентификатор (ссылку) сущности "уровень образования". В данном примере для идентификации сущности мы располагаем:
- классом сущности - "уровень образования" (идентификатор класса:
https://semantics.lipers24.ru/онтология/уровеньОбразования), - идентификатором признака "Уровень" (сокращенное название уровня образования) в RDF-представлении
lip:сокращенноеНазвание, - значением данного признака для искомой сущности (например, "НО" или "СО").
 Рис. 2. Данные для идентификации сущности
(для увеличения - кликните на картинку)
Рис. 2. Данные для идентификации сущности
(для увеличения - кликните на картинку)
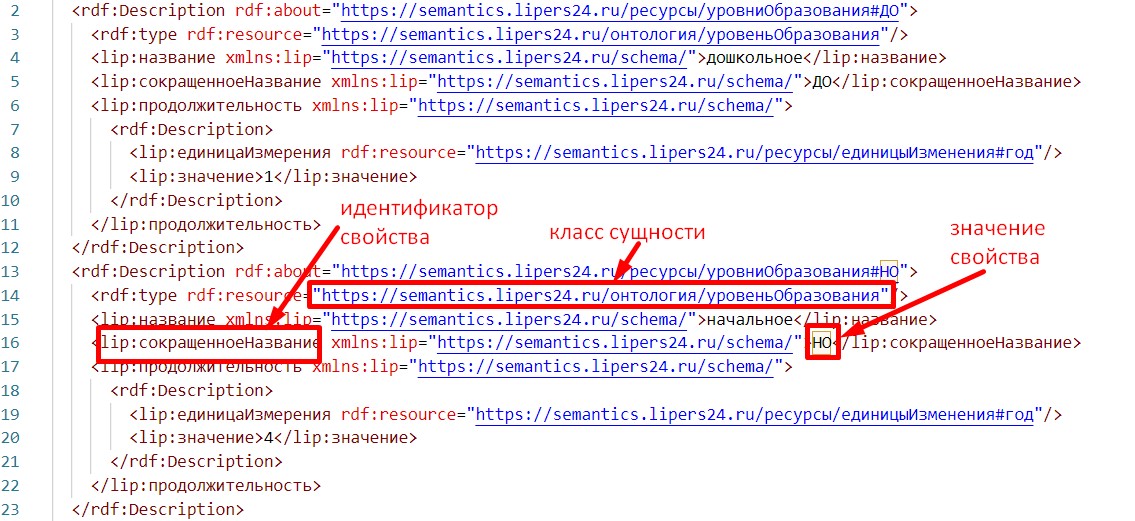 Рис. 3. Элементы RDF-представления для идентификации сущности
(для увеличения - кликните на картинку)
Рис. 3. Элементы RDF-представления для идентификации сущности
(для увеличения - кликните на картинку)
Отображения
Итак, граф с исходными данными представляет собой дерево, в котором можно выделить уровни иерархии. Узлы на каждом уровне иерархии имеют имена. Каждый узел соответствующего уровня может быть идентифицирован парой: "имя узла", "порядковый номер узла". Узлы дерева, у которых нет потомков, имеют строковые значения. Таким образом, каждый узел может быть однозначно идентифицирован среди всех узлов с помощью цепочки идентификаторов всех его предков плюс идентификатор узла на текущем уровне.
Например, узел со значением "гуманитарный" будет иметь уникальный путь внутри графа
./file/table/row[2]/cell[4]- это так называемый XPath-запрос (запрос на языке XPath).
Исходный граф можно разбить на множество отдельных фрагментов, таким образом, чтобы каждый узел графа был узлом соответствующего фрагмента. Так мы получим множество фрагментов исходного графа, каждый из которых сам будет деревом. Эти фрагменты можно объединить в подмножества - слои - по уровням, на которых находятся их корневые узлы.
Слои должны чередоваться в порядке соответствующем структуре RDF-триплета: "слой сущностей" -> "слой имен признаков" -> "слой значений признаков". При этом "слой значений признаков" может содержать либо текстовые значения признаков, либо описания вложенных сущностей, либо значения признаков сущностей из другого графа. Последний вариант предполагает, что в генерируемом триплете значение признака будет ссылкой (идентификатором) сущности, описанной в другом наборе данных (графе-дереве).
Соответственно схема на языке CCCR представляет собой функцию, отображающую исходный граф с данными в RDF-представление (набор RDF-триплетов). При этом каждое действительное сочетание элементов трех последовательных слоев исходного графа: "слой сущностей" -> "слой имен признаков" -> "слой значений признаков", образуют один RDF-триплет. Количество возможных RDF-триплетов будет равно количеству элементов последнего слоя - "слоя значений признаков".