Информация, данные, контекст
Для чего нужны схемы (инструкции) на языке CCCR
(примерное время чтения 10 минут)
Здесь мы изложим некоторые соображения о том, какие трудности возникают при обмене информацией между живыми людьми и между машинами, а также и о том, какие возможности существуют для решения этих проблем.
Информация и ее передача
В терминах Клода Шеннона информация - это нечто способное снижать для наблюдателя энтропию наблюдаемой системы. Информацию о своей системе один "наблюдатель" может передать другому "наблюдателю", чтобы помочь "коллеге" снизить энтропию его системы. Естественно, что это возможно, если системы эквивалентны в аспекте передаваемой информации.
Пример. Причиной повышенного износа колеса автомобиля как правило является нарушение параметров наклона колеса в горизонтальной плоскости - так называемого угла "схождения". Наличие информации об этом у начинающего автомобилиста позволит быстрее установить и устранить причину проблемы.
Мы исходим из того, что нашу - "земную" - информацию можно передавать только с помощью знака, "записанного" на каком-то носителе. Улыбка - это тоже знак, носителем которого выступает наше выражение лица. Но здесь мы будем рассматривать информацию, передаваемую в виде наборов символов - текста. Такой текст, который обычно имеет определенную структуру (например, табличную или вложенных списков), мы будем назвать данными.
Естественно, что информация должна быть записана в данных так, чтобы быть понятной адресату. Для этого у собеседников (отправителя и адресата) должно быть соглашение о том, как представлять информацию с помощью набора знаков. Это соглашение устанавливает связь между "информационной сущностью" и набором знаков для ее отображения. Полный набор таких соглашений, достаточных для обмена информацией между отправителем и получателем, можно назвать языком. Здесь мы рассматриваем язык чисто утилитарно, как средство кодирования информации в виде знаков для целей хранения, обработки и передачи. "Атомы" - "слова" - составляют семантику языка. Семантические единицы с помощью правил грамматики языка образуют высказывания - конструкции собственно и передающие информацию.
На основании приведенных утверждений может показаться, что достаточно иметь соглашения о семантике и грамматике для продуктивного обмена информацией. Но вот, что происходит на практике:
Мы были оба.
Я у аптеки!
А я в кино искала вас!
Так, значит, завтра
На том же месте, в тот же час!Явно, что в этом высказывании еще чего-то не хватает. Не хватает соглашения о том, что собеседники понимают под указанием на "то же место". Соглашение о семантике и грамматике никак не помогает разрешить данное затруднение. Для разрешения данного затруднения нужна еще некоторая информация, которой должны обладать собеседники до того, как начнут кодировать и расшифровывать высказывание. Такую информацию, необходимую для интерпретации (расшифровки) высказывания, можно назвать контекстом.
Сокрытие контекста
context-unbound data
Современные системы и стандарты передачи информации создавались и развивались как средства взаимодействия военных, и уже постольку-поскольку становились частью "гражданского оборота". Теоретические основы, прикладные методы и конкретные стандарты передачи информации разрабатывались известными теперь учеными как К. Шеннон, А. Тьюринг, В. Котельников (здесь, например, мы можем вспомнить судьбу теоремы "Уиттекера-Котельникова-Шеннона") в интересах армии. Это важное замечание, которое, на взгляд автора, открывает путь к пониманию нынешнего странного состояния гражданских систем организации, хранения и передачи данных.
При передаче информации между военными принципиально важно сделать сообщение недоступным для расшифровки (мы скажем - содержательной интерпретации) в случае его перехвата противником. Такая задача защиты является для военных заказчиков даже более значимой, чем собственно задача передача информации. В самой основе взаимодействия предполагается, что военные "собеседники" обладают полным контекстом, необходимым для понимания высказывания, переданного в сообщении. При этом для целей сокрытия часто достаточно применить формулировку, которая была бы сильно связанна со специфически контекстом, чтобы даже незашифрованное высказывание не могло быть понято посторонним лицом.
«Малая Касательная 16 Александру Корейко графиня изменившимся лицом бежит пруду»
телеграмма О. Бендера "Золотой теленок" И. Ильф и Е. Петров (1931)«Мы используем наш национальный язык, а именно тувинский, чтобы в случае радиоперехвата противник не смог понять, о чем идет речь», — из интервью инструктора отделения связи Николая Чамьяна.
Таким образом, создаваемые системы передачи информации (а вместе с ними и хранения, и обработки) не только не заботились о развитии способов передачи контекста, но наоборот старательного его скрывали. Поэтому и гражданские решения, "питавшиеся" разработками военных, вынужденно строились по такому же принципу: обмен контекстом должен происходить отдельно от передачи информации. Поэтому принципы и методы записи информации не только не заботились о "привязке" сообщений к контексту, но и избегали даже случайной возможности такого развития событий. Соответственно и системы хранения данных (их еще часто называют "системы хранение информации", что верно лишь от части) "заточены" на работу с такими "свободными" от контекста - "безконтекстными" - данными (context-unbound data).
Для случаев, когда мы хотим передать информацию незнакомому с контекстом адресату такие данные и способы их организации создают значительную проблему. Для ее решения в "классических" гражданских, а по сути "допиленных" квази-военных, системах используют так называемые "метаданные", которые построены по тем же принципам, что и сами данные. Поэтому те из вас, кто читает настоящий текст с самого начала, резонно спросят: "А как же интерпретировать метаданные не имея метаданных о метаданных?". В общем, понятно, что наличие метаданных тоже дает решение лишь частичное - теоретически позволяет уменьшить объем контекста, который надо передавать вне каналов обмена информацией. Но появление отдельно живущего массива метаданных создает другую существенную проблему - поддержание их в актуальном состоянии.
Вот здесь мы привели примеры того, какие проблемы в жизни создают "бесконтекстные" системы работы с информацией.
Компрометация контекста
context-rich data
Одна из основных проблем обмена информацией является неоднозначность семантики, которая используется при записи информации в виде набора данных. Здесь мы попробуем показать возможность "обогащения" данных сведениями о контексте. Такое "обогащение" позволяет в значительной степени преодолеть трудности интерпретации семантики данных при попытках извлечь из них информацию. Именно для создания компактных инструкций превращения пользовательских данных в "семантически-обогащенные" RDF-представления разработан язык CCCR.
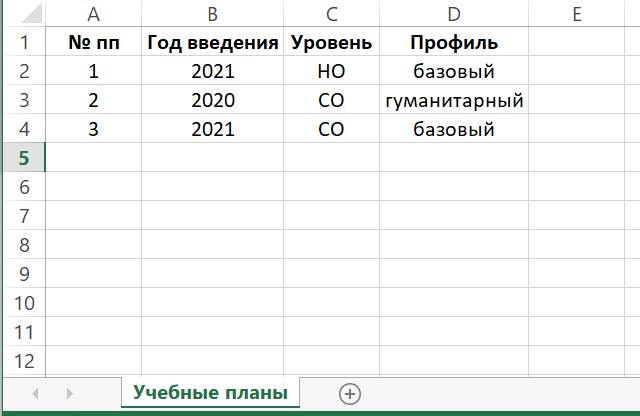
Рассмотрим описание набора некоторых сущностей, который представлен в виде иерархической структуры. Например, таблица представленная в виде дерева:
{kind=link}
<file>
<table label="Учебные планы">
<row>
<cell label="№ пп">1</cell>
<cell label="Год введения">2021</cell>
<cell label="Уровень">НО</cell>
<cell label="Профиль">базовый</cell>
</row>
<row>
<cell label="№ пп">2</cell>
<cell label="Год введения">2020</cell>
<cell label="Уровень">СО</cell>
<cell label="Профиль">гуманитарный</cell>
</row>
<row>
<cell label="№ пп">3</cell>
<cell label="Год введения">2021</cell>
<cell label="Уровень">СО</cell>
<cell label="Профиль">базовый</cell>
</row>
</table>
</file>Это фрагмент реестра учебных планов конкретной школы. Реестр содержит описания сущностей - учебных планов. У каждой сущности (в данном случае - учебного плана) есть набор признаков. Эти признаки имеют имена: "№ пп", "Год введения", "Уровень", "Профиль".
В примере нам известен тип (класс) сущностей - учебные планы, а имена признаков имеют человекочитаемое представление. Благодаря этому мы можем утверждать, что нам известен контекст для интерпретации. В том числе имя признака "Уровень" мы интерпретируем как "уровень образования", которому относится учебный план. Знание контекста дает нам возможность понимать и значения признака "уровень образования": "НО" - начальное образование, "СО" - среднее образование. Таким образом, у нас есть возможность содержательно интерпретировать весь представленный набор данных, то есть извлечь информацию.
Но приведенная выше запись может быть представлена в другой форме с гораздо менее выразительной семантикой. Например, так:
<table>
<up>
<n>1</n>
<y>2021</y>
<u>НО</u>
<p>базовый</p>
</up>
<up>
<n>2</n>
<y>2020</y>
<u>СО</u>
<p>гуманитарный</p>
</up>
<up>
<n>3</n>
<y>2021</y>
<u>СО</u>
<p>базовый</p>
</up>
</table>Для интерпретации такого набора данных уже потребуются более подробные пояснения. И вообще подобных способов записи информации об одной и той же сущности может быть сколько угодно много. При этом следует учитывать, что в реальных случаях массивы данных содержат информацию о десятках и сотнях классах сущностей с сотнями или тысячами признаков (например, фрагмент информационной системы вуза с реестром контингента учащихся). Поэтому поддержание реальной базы данных в "жизнеспособном состоянии" требует не только ввода данных, но и ведения исчерпывающего массива из метаописаний, которые выполняют роль связующего звена между конкретной семантикой и контекстом. Без такого метаописания ("привязки к контексту") оперировать данными невозможно - их информационная ценность как шенноновском, так и в интуитивном понимании смысла слова "информация", равна нулю.
Модель RDF позволяет организовывать данные так, чтобы для извлечения информации не требовалось знание специфического контекста, в котором эта информация создавалась. Можно сказать, что контекст "помещен" внутрь самих данных.
В этом, пожалуй, состоит основная задача RDF. Вторая задача RDF скорее уже вспомогательно-техническая - принять соглашение о способе представления такой ("обогащенной" контекстом информации). В концепции RDF для представления информации используется конструкция, которую называют триплет. Триплет, как следует из термина, состоит из трех частей: "субъект"-"предикат"-"объект". "Субъект" - знаковое обозначение сущности (ее уникальное имя, глобальный идентификатор сущности), "предикат" - знаковое представление имени признака, "объект" - значение признака. И "субъект", и "предикат" должны быть уникальным в масштабах информационного Универсума - "информационной Ойкумены". "Объект" - значение признака - может быть одним из двух типов: строка символов или идентификатор сущности (ссылка на сущность).
Рассмотрим преобразование иерархического представления данных в RDF-представление. В нашем примере описаны три сущности одного типа - учебные планы. Описание одной сущности выглядит так:
<row>
<cell label="№ пп">1</cell>
<cell label="Год введения">2021</cell>
<cell label="Уровень">НО</cell>
<cell label="Профиль">базовый</cell>
</row>Как мы отмечали выше, в нашем примере сущность - учебный план - имеет четыре признака. Содержательно значимыми признаками являются три их них: "Год введения", "Уровень", "Профиль". Признак с именем "№ пп" в таблице выполняет роль идентификатора. Таким образом, каждый учебный план в нашей модели может быть описан тремя триплетами примерно так:
<1> - <Год введения> - "2021"
<1> - <Уровень> - "НО"
<1> - <Профиль> - "базовый"По принятым соглашениям при записи триплетов в виде текста идентификаторы сущностей заключают в треугольные скобки <...>. Так как признаки также являются сущностями, то и их имена (идентификаторы) мы заключаем в треугольные скобки как и идентификатор (имя) описываемой сущности. Строки традиционно заключают в кавычки.
Прочитать такую запись первого триплета можно следующим образом: "Сущность с идентификатором <1> имеет признак <Год введения>, значение которого равно "2021".
Такая запись без дополнительных сведений о контексте дает мало содержательной информации. Собственно вопрос интеграции контекста в "внутрь" данных мы рассмотрим после описания основ представления RDF-триплетов в машиночитаемом виде. Забегая вперед скажем, что этот вопрос решается не на уроне синтаксиса, а на уровне создаваемых с помощью него конструкций. Поэтому естественно, что запись RDF не обязательно содержит информацию о контексте, но в таком случае преимущества ее использования, естественно, теряются.
Для машинной обработки триплетов приняты стандарты их записи - сериализации. Стандартов сериализация RDF-триплетов принято несколько, и каждый из них имеет перед конкурентами как преимущества, так и недостатки. Здесь мы будем использовать только один формат машиночитаемого представления RDF-триплетов - RDF/XML.
Приведенная выше запись триплетов в формате RDF/XML будет выглядеть примерно так:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="1">
<ex:годВведения xmlns:ex="https://example.com/">2021</ex:годВведения>
<ex:уровеньОбразования xmlns:ex="https://example.com/признаки/">НО</ex:уровеньОбразования>
<ex:профильУчебногоПлана xmlns:ex="https://example.com/признаки/">базовый</ex:профильУчебногоПлана>
</rdf:Description>
</rdf:RDF>Фраза "запись выглядит примерно так" указывает на то, что один и тот же набор триплетов может быть сериализован в RDF/XML разными способами, сохраняя при этом содержание информации, которую он несет.
В частности, в данном случае было нашим выбором установить идентификаторы для обозначения признаков (задать имена признаков). <ex:годВведения xmlns:ex="https://example.com/признаки/">2021</ex:годВведения> предполагает, что свойство с именем label="Год введения" приведено к ex:годВведения в пространстве имен (namespace) https://example.com/признаки/. Само пространство имен https://example.com/признаки/ также является нашим произвольным выбором.
Конструкция rdf:about="1" как можно понять является указанием на идентификатор сущности (субъект в терминологии RDF). Очевидно, что идентификатор "1" трудно считать уникальным. Для решения этой проблемы в концепции RDF рекомендуется использовать для каждой сущности уникальный глобальный идентификатор - URI.
"Глобальность" предполагает независимость от контекста. В приведенном выше примере "1" является уникальным идентификатором только в данной таблице, но ни как не в масштабах "Универсума". Поэтому правильным вариантом будет установка глобального идентификатора URI, например, так rdf:about="https://example.com/сущности/учебныеПланы#1" или rdf:about="https://example.com/сущности/учебныеПланы#2021-НО-базовый", где https://example.com/сущности/учебныеПланы# - идентификатор (имя) набора сущностей (списка учебных планов), а 2021-НО-базовый - уникальный идентификатор конкретного учебного плана в наборе (списке планов).
Кроме того, значимым условием правильной интерпретации данных является знание, к какому классу онтологии относится описываемая сущность. В RDF для этого приняты особые признаки сущностей, в частности, такой rdf:type - он указывает к какому типу (классу) относится данная сущность. В нашем примере тип (класс) сущности можно обозначить как "учебный план". Тогда дополнительный признак может быть <rdf:type resource="https://example.com/онтология/УчебрныйПлан">. Теперь "обогащенное" RDF-представление наших триплетов для одного учебного плана может выглядеть так:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="https://example.com/сущности/учебныеПланы#2021-НО-базовый">
<rdf:type resource="https://example.com/онтология/УчебныйПлан">
<ex:годВведения xmlns:ex="https://example.com/признаки/">2021</ex:годВведения>
<ex:уровеньОбразования xmlns:ex="https://example.com/признаки/">НО</ex:уровеньОбразования>
<ex:профильУчебногоПлана xmlns:ex="https://example.com/признаки/">базовый</ex:профильУчебногоПлана>
</rdf:Description>
</rdf:RDF>Отметим, что типы (классы) сущностей сами являются сущностями и следовательно могут быть описаны. В описание типов (классов) кроме человеко-читаемых пояснений можно включать связи с более общими типами - "родительскими классами". Это позволяет сроить развитые онтологии и таксономии. В нашем примере класс
https://example.com/онтология/УчебныйПланможет быть подклассом более общего класса "документы" -https://example.com/онтология/Документ.
Но что в указанной записи значит "НО" в значении признака ex:уровеньОбразования. Интуитивно можно предположить, что "НО" обозначает "начальное образование", ...

Для исключения неопределенности мы можем в качестве значения признака ex:уровеньОбразования использовать указатель (идентификатор) на сущность, которая в свою очередь содержит описание соответствующего уровня образования <ex:уровеньОбразования resource="https://example.com/сущности/уровниОбразования#НО"/>. Таким же образом, значение года введения учебного плана и его профиль можно обратить в указатели на соответствующие сущности. В этом случае мы можем получить и сведения о сущностях, с которыми связан соответствующий учебный план. Например, для уровня образования мы можем выяснить полное его название, а также продолжительность в годах и нормативный акт, которым это установлено и т.д.
Вот как примерно выглядит схема (инструкция) на языке CCCR, которая позволяет превратить таблицу со списком учебных планов школы в "обогащенное" RDF-представление.
Мы также в нашем информационном "Универсуме" можем установить описания признаков, т.е. ввести признаки признаков. Это могут быть и пояснения для лучшей человекочитаемости, и, что важно, инструкции для машинной обработки значений признаков. В частности, можно установить критерии валидации значений признаков. Например, для года введения учебного плана можно установить, что это должно быть целое положительное число не меньше, чем 2010. Кроме того, можно указать, что данный признак является эквивалентом ("same as...") признака из какого-то внешнего общепринятого словаря (owl:sameAs):
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="https://example.com/признаки/годВведения">
<rdf:type resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property">
<rdfs:label xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">Год введения введения документа</rdfs:label>
<owl:sameAs xmlns:owl="http://www.w3.org/2002/07/owl#" resource="https://schema.org/copyrightYear"/>
<rdfs:range xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" resource="http://www.w3.org/2001/XMLSchema#positiveIteger"/>
<rdfs:range xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#">
<rdf:Description>
<xs:minInclusive xmlns:xs="http://www.w3.org/2001/XMLSchema">2010</ex:minInclusive>
</rdf:Description>
</rdfs:range>
</rdf:Description>
</rdf:RDF>То ради чего
context-unbound source
Теперь, используя на наше воображение, представим "контекстно-независимую" последовательность шагов для извлечения информации из "семантически-обогащенных" и "контекстно-несвязанных" данных.
Допустим нам надо из данных описанного выше примера узнать профили учебных планов среднего образования, которые были введены в 2021. Для этого, как мы договаривались, у нас есть только окно (консоль) для ввода запроса к RDF базе, и мы ничего не знаем про структуру и семантику данных, которые в ней хранятся. В этом случае логика построение запроса может быть такая:
- Запросить из базы данных все имеющиеся типы (классы) сущностей.
- Из полученного списка типов, найти такой, который по человеко-читаемому описанию соответствует искомому - "учебный план".
- Выбрать все сущности типа "учебный план".
- Для всех найденных сущностей типа "учебный план" запросить все признаки, которые у этих сущностей встречаются.
- Из полученного списка имен признаков на основе человеко-читаемого описания признаков найти такие признаки, которые содержат информацию о годе введения, уровне образования и профиле учебного плана.
- Для всех сущностей "учебный план" со значениями признаков "год введения" равным "2021" и "уровень образования" соответственно "среднее образование" и вывести значение признака "профиль учебного плана".
Специфический язык запросов к семантически-обогащенным данным называется SPARQL. С его помощью все указанные выше шаги можно "упаковать" в один запрос.
Итоговый запрос, сконструированный по приведенному алгоритму, может выглядеть примерно так (попробовать - для запуска в открывшемся по ссылке окне запроса нажать на черный треугольничек):.
PREFIX : <https://semantics.lipers24.ru/schema/>
PREFIX онтология: <https://semantics.lipers24.ru/онтология/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?учебныйПлан ?профиль WHERE {
GRAPH ?g {
?учебныйПлан rdf:type онтология:учебныйПлан;
:уровеньОбразования <https://semantics.lipers24.ru/ресурсы/уровниОбразования#СО>;
:годВведения "2021";
:профильУчебногоПлана ?профиль
}
}Таким образом, при соблюдении некоторого минимального набора требований к RDF-описаниям, можно практически полностью исключить зависимость информации, хранящейся в базе данных, от специфического контекста. Это существенно расширяет возможности для обмена информацией не только "в пространстве", но и "во времени". В том числе становится возможным сохранить жизнеспособность информационной системы предприятия и после того, как уволился администратор (архитектор, системный аналитик) базы данных.
Шаг вперед
В информационной модели организации (вообще некоторого сообщества) полезной практикой, которая позволит сделать процесс поиска еще более компактным, является использование так называемого "семантического контракта". Его можно охарактеризовать как некоторое соглашение, содержащие принятые сообществом правила представления информации в коллективном "информационном Универсуме" (некоторые примеры сценариев использования "семантического контракта" для обмена информацией).