Как?
О том, как "работает" язык CCCR
Мотивы, толкнувшие (скорее, вынудившие) нас на изобретение "еще одного нечеловеческого языка" состоят в отстрой необходимости иметь инструментарий для превентивного подавления искусственно создаваемой энтропии (более подробно о мотивах см. здесь). Здесь мы скажем пару слов о том, как работает технология, в основе которой лежит язык CCCR и в общих чертах обозначим область применения технологии.
Рукотворная информация
Внутри того, что мы обыденно называем "информацией" присутствуют различные явления и сущности, которые в различных контекстах обозначают словом "информация". Известная формализация термина "информация" в частности преложенная Клодом Шенноном указывает на способность информации уменьшать неопределенность - энтропию (возможное количество исходов какого-то предстоящего события). Например, я собираю в лесу грибы. Если мне известно из опыта или школьного курса биологии, что организм гриба функционирует через взаимодействие с корневой системой дерева, то я буду знать, что вероятность найти гриб поблизости от дерева выше. Благодаря информации неопределенность поиска гриба уменьшается - говорят, что наличие подобной информации у конкретного грибника снижает для него энтропию события "найти гриб" в каждый момент времени его прогулки в лесу. Для нас важна "персональность", "субъектность" информации (равно как и ее антипода - энтропии). В системе социальных отношений нам предписано заботиться о "снабжении" информацией окружающих в соответствии с нашими социальными ролями. Я, как преподаватель, выдаю студентам задание для подготовки к предстоящему семинару. С точки зрения теории информации я устраняю для студентов неопределенность (снимаю энтропию) события "будут ли меня спрашивать на семинаре" (точно будут) и всех событий "будут ли спрашивать по такой-то теме" (точно будут спрашивать по заданной, но по всем остальным не будут).
В нашем "мире социального взаимодействия" нет информации "как таковой", "имманентной" или "самой в себе". Человек решает, что создает является для него информацией, человек и устанавливает факт "рождения" информации своим решением. Руководитель назначает время и место проведения совещания. Покупатель отправляет онлайн заказ в интернет-магазин. Токарь делает отметку в наряд-заказе об изготовлении детали. Эта информация рождается для окружающих в виде знака в конкретном месте и в конкретное время.
Такая информация является актом личного выбора, актом воли. Это первое важное обстоятельство - мы рассматриваем информацию, которая является актом воли человека при реализации человеком своей социальной роли. Человека - установившего ограничение в виде сообщения какой-либо значимой для окружающих информации мы будем называть "субъектом информации" (или "родителем"). Фиксируя акт "рождения" информации, мы также предполагаем наличие "места рождения" и "времени рождения" информации.
Второе важное обстоятельство состоит в том, что информация в нашем "социальном пространстве" появляется в форме знака. Только такая - представленная знаком - информация может служить для нас объектом обработки. Здесь мы рассматриваем случаи "рождения" информации в виде электронного знака в какой-то электронной системе (на практике чаще всего это "эксель" или "ворд", но могут быть т.н. "базы-данных", АРМы во всяких "крутых ERP"). Такой знак мы будем называть "первичная информация". В дальнейшем "первичная информация" может проявиться в разных местах и формах - такие различные формы (которые могут существенно отличаться от первично внесенного знака) мы будем называть "представлениями информации".
Человек оформляет информацию знаком в расчете на ее последующее использование. Так как это последующее использование может быть многократным, то мы будем использовать термин "переиспользование".
Рукотворная энтропия
Переиспользование информации, о которой мы здесь ведем речь, на практике осуществляется (почти всегда) путем многократного копирования - в прямо смысле "копипаста". Эта вынужденная ("не от хорошей жизни") практика несет в себе массу сложностей: и трудоемкость (не только нажатия сочетания клавиш "Ctrl C - Ctrl V", но в первую очередь поиска источника того, что нужно "копипастить"), и ошибки, и порождаемая ошибками вторичная трудоемкость (по поиску ошибки). Но гораздо большую опасность и фатальные последствия несет в себе "повторное рождение" информации.
Рассмотрим пример. Студент при поступлении в вуз заполняет заявление с личными данными, где указывает дату своего рождения. Эту дату проверяет ответственный сотрудник приемной комиссии, и сверив с оригиналом паспорта вносит в т.н. "базу данных учета контингента". Потом в разных местах и ситуациях пребывания студента в вузе дата рождения требуется в разных документах и "базах". Её иногда копируют непосредственно из "базы контингента", естественно, с ошибками. Но так как не только лишь у всех сотрудников вуза есть доступ к базе контингента, то дату часто вынуждены перезаписывать "со слов" или "по памяти". В результате естественных ошибок ввода у одного студента нередко в разных "базах" и документах будут разные даты рождения (кто не верит, может проверить в любом (!) вузе). И в таком случае, в отличии от "копипаста" из единого источника, установить какая дата является правильной невозможно. Приходится цикл ввода информации повторять. Те кто знает ситуацию по своему опыту или обладает некоторым воображением может понять, что данная ситуация становится вообще драматичной, в силу того, что выверка проходит только в одном сегменте базы. При этом в других может оставаться отличающаяся информация о дате рождения. Потом, когда это обнаружат, опять будет не ясно, какая информация верная. Таким образом, можно смело и одновременно с прискорбием утверждать, что в любой момент времени любая база данных построенная на указанных принципах не может быть признана достоверной. Во многих "база данных" есть места, где недостоверная информация ведет не только к перерасходу труда, но и к уголовно-правовым последствиям. Вот идентификатор студента - обычно номер зачетки. Применение к нему методов "работы" аналогичных приведенным выше с необходимостью приведет к "задовению" и "затроению" студентов в "базах" и в документах (кому интересно, пройдитесь по базе данных контингента любого вуза). "Но если у одного из 100 студентов будет ошибка в дате рождения или в номере зачетки - это же не такая большая проблема в том смысле, что она легко исправима". Человек, который выскажет такое утверждение, никогда не занимался обработкой чужой информации. Для всех остальных понятно, что потенциальное наличие одной ошибки в неизвестной записи (вы же не знаете в дате рождения какого студента ошибка) делает весь массив информации непригодным. Те кто отвечают за последствия по нормам уголовного кодекса знают это и вынуждены перед любым юридически значимым использованием информации и "базы данных" (например, изготовление дипломов об окончании) проводить выверку ключевых реквизитов. Такая выверка фактически есть повторный ввод всего массива информации. Подобные выверки в отношении, например, дат рождений студентов происходят неоднократно за время учебы. Но к счастью выверки проводят не сами ЛПР, а их подчиненные. А на практике мы имеем фантастические массивы многократно дублированных данных, которые содержат нулевой объем с точки зрения "шенноновской" теории информации. Что с вуза взять? Верно - для вуза ведение баз данных вещь вспомогательная. Главная задача вуза - учить. Но в государстве есть структуры, основной и единственной функцией которых, является ведение баз данных. Автор этих строк лично сталкивался и участвовал в исследовании коллизий проведения в электронных системах платежей в "супернадежной" системе государственного ведомства, единственной функцией которого является собственно организация электронной системы проведения платежей. Там принцип организации информации тот же и последствия те же.
"Когда началась специальная военная операция, мы с вами увидели, что местами у нас в военкоматах много бардака... Речь идет о том, что мы должны упорядочить систему учета и призыва тех, кто должен служить в армии." пресс-секретарь президента РФ Д. Песков о создании реестра военнообязанных, 12.04.2023
Точно такая же ситуация в коммерческих организациях по поводу учета хозяйственных операций в электронной системе условно назовем "1Ц". Там крайне проблематично найти хотя бы один регистр учета без внутренних противоречий (надо основательно поискать, чтобы найти хотя бы небольшой фрагмент непротиворечивой информации в такой системе).
Первый пример - постановка задачи
Перейдем к обсуждению конструктивной стороны технологии на примере. Рассмотрим "любимую" педагогами документацию по организации учебного процесса вуза. Рабочая программа дисциплины (один из самых массовых документов) "привязана" к учебному плану, который в свою очередь принят ученым советом вуза. В рабочей программе надо указать реквизиты решения ученого совета (на самом деле в рабочей программе подобных "импортируемых" реквизитов более 30 штук). Если в учебный план вносились изменения, то актуальные реквизиты решения ученого совета будут обновляться. Учебный план "привязан" к образовательному стандарту - если изменился стандарт, возникнут изменения во всей цепочке "образовательный стандрат" -> "учебный план" -> "рабочие программы". Реквизиты путем "Ctrl C - Ctrl V" кочуют по документам. Поддерживать весь массив в актуальном состоянии требует немыслимых трудозатрат.
В приведенном примере рассмотрен эмоционально волнующий вузовских преподавателей "кейс" генерации бессмысленных документов. Из примера даже непосвященный человек может понять, что поддерживать в актуальном состоянии указанные документы просто невозможно. А в силу их практической ненужности еще и бессмысленно.
Другое дело если мы говорим об информации, которая реально нужна для организации работы. Например, расписание в школе. Школьное расписание (вы удивитесь) меняется каждый день. Центральным источником информации о расписании могла бы выступать информационная система школы (какой-нибудь "электронный журнал"). Но в реальности систем, которые можно было бы использовать для первичного ведения расписания школы, нет. Расписание ведут в таблицах на бумаге, в ворде или в экселе. Потом из первичных носителей эту информацию транслируют в разные представления - бумажные, электронные и т.п. Так как расписание в школе меняется каждый день (! - восклицательный знак для тех, кто не работал в школе и не знаком с таким фактом), то поддержание всех представлений в актуальном виде - это целая отдельная организационная задача, которую сам факт наличия некоего электронного журнала не решает (эта ремарка для читателей из числа ответственных сотрудников муниципальных органов управления образованием).
Спасение утопающих
Из изложенного выше нам кажется, что для примера с расписанием было логичным иметь одну точку "хранения" расписания, из которой оно бы раскидывалось во все нужные представления (для детей, для учителей, для учета рабочего времени бухгалтерией и т.п.).
Наш подход работает так:
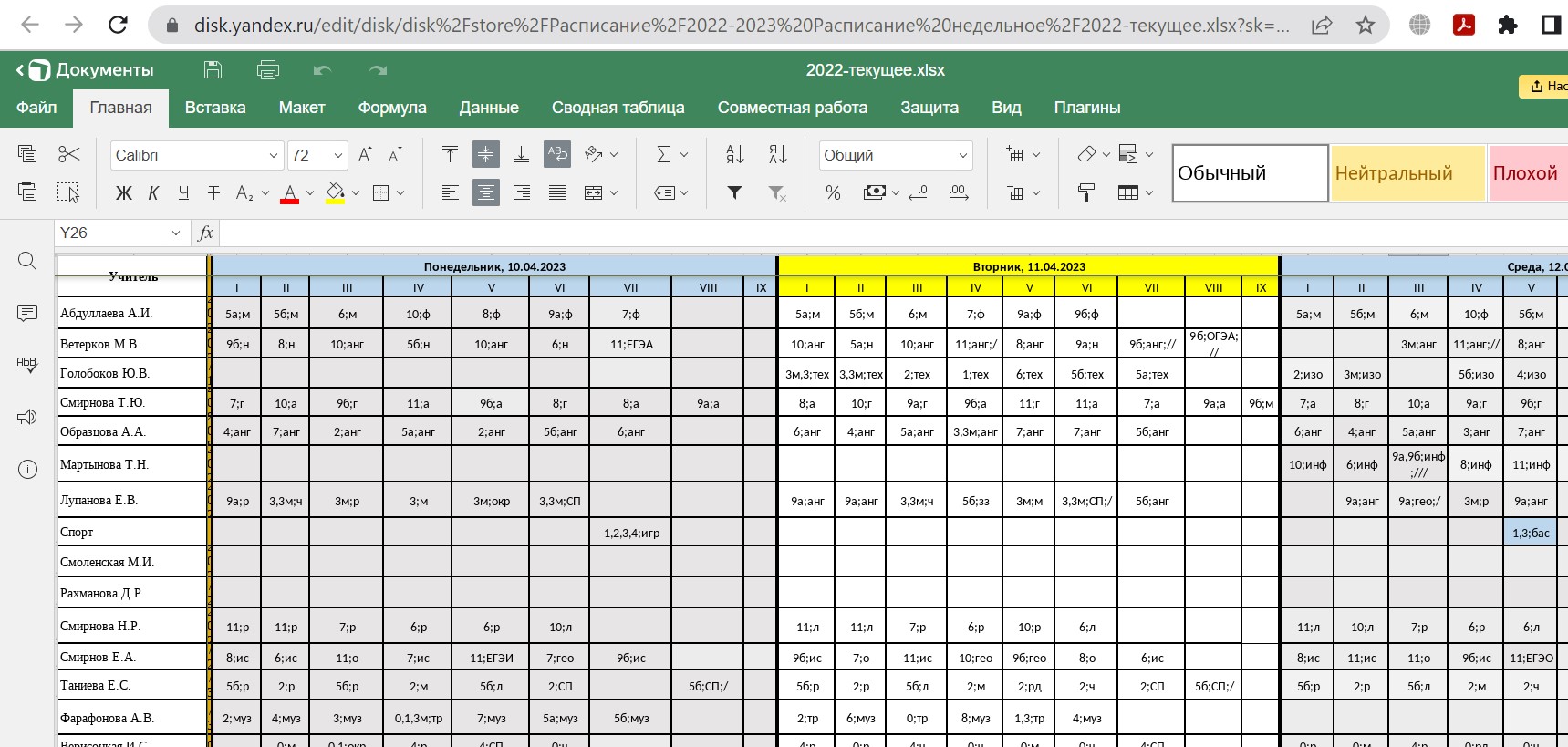
- ответственный за расписание завуч ведет его в привычной форме в файле ексель или ворд, который с его личного компьютера синхронизируется с его личной учетной записью облачном хранилище школы; вот как раз для публикации первичного (в экселе или ворде) представления расписания и нужна схема преобразования в RDF-представление; для описания этих схем нам и пришлось разработать язык CCCR;
- система , обнаружив изменения в файле автоматически извлекает из него информацию и переводит универсальное RDF-представление из обновляет в RDF-хранилище;
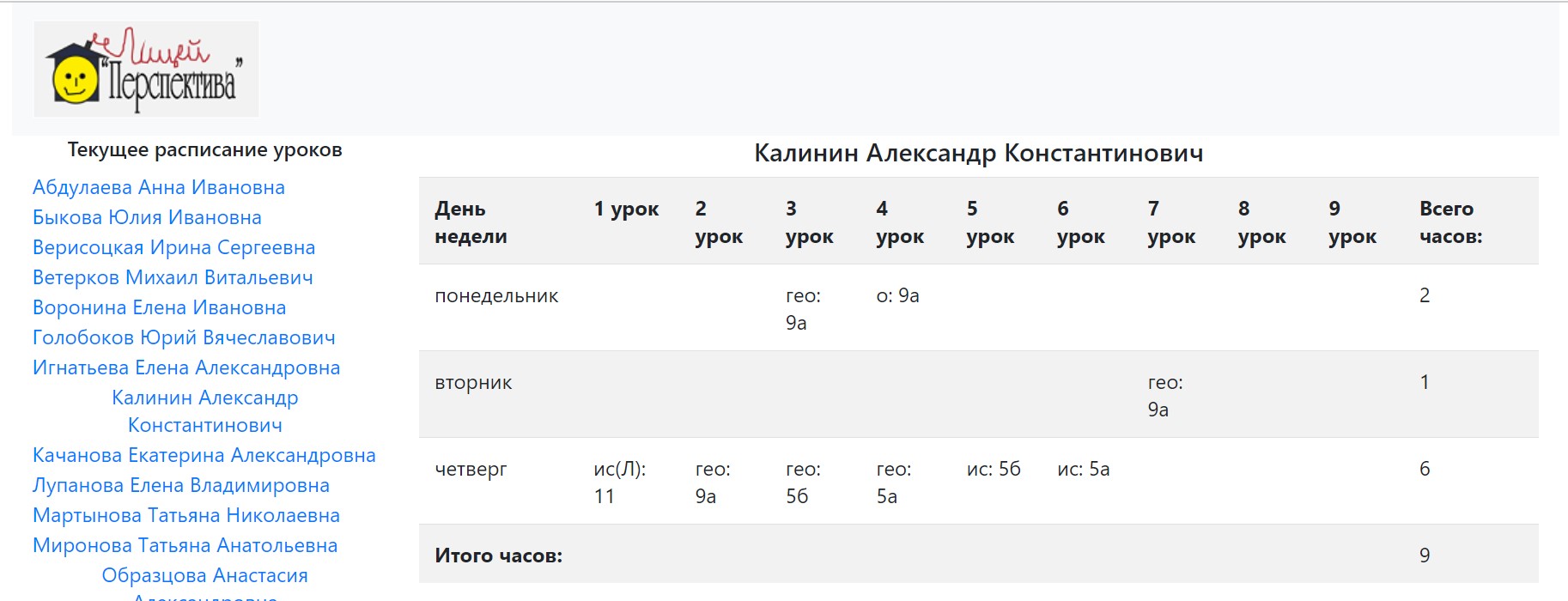
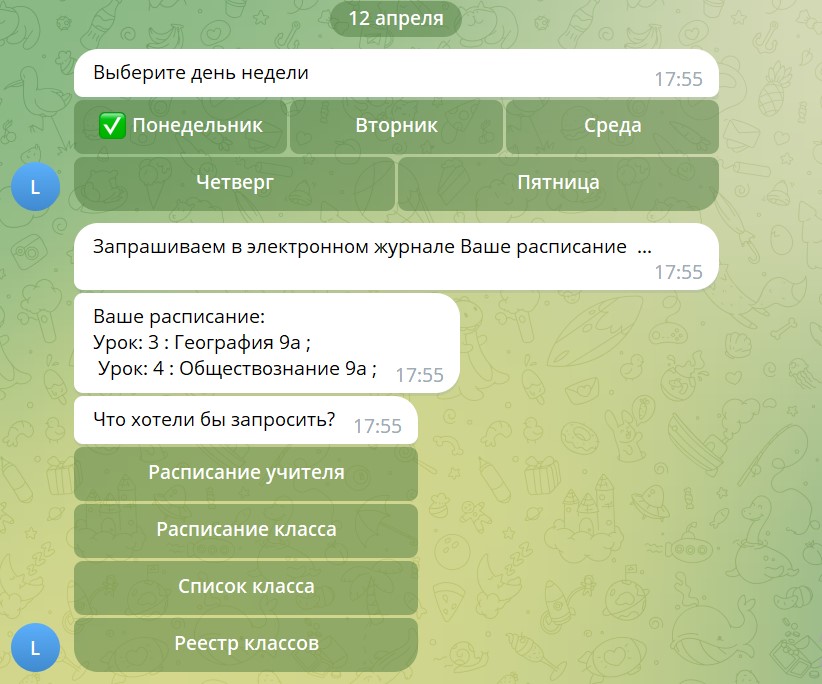
- эта же система TRaC по требованию пользователей формирует нужные представления для школьников, для учителей; в том числе может оповещать через чат-бота заинтересованных лиц, подписанных на обновления.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
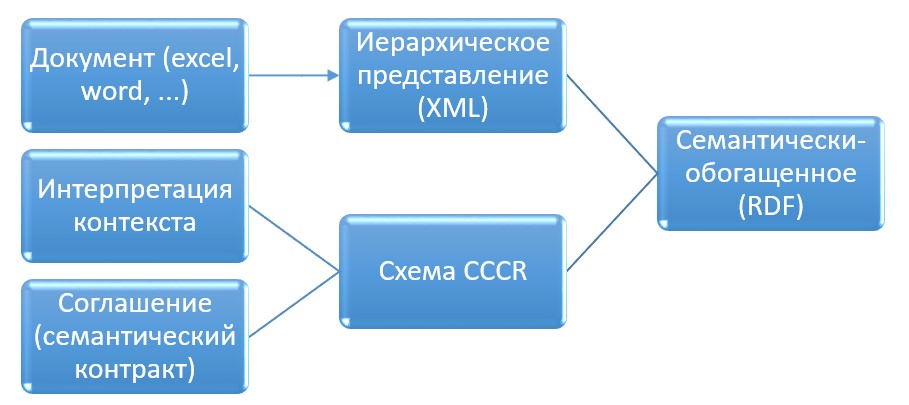
Рис. 1. Схема трансформации данных в RDF-представление
Таким образом, мы имеем одну точку хранения первоисточника - у "родителя" исходной информации. После "рождения" информации (в приведенном примере - после внесения изменений в расписание) все ее представления (здесь мы подчеркнем слово "все") появляются в момент обращения пользователя и используют первоисточник. Поэтому ни в каком представлении не может появится неактуальная информация - это первый эффект. Второй эффект - "стоимость" человеческих трудозатрат на извлечение информации в буквальном смысле нулевая.
Пример второй (для иллюстрации)
Преподаватель подготовил набор вопросов для тестирования студентов по предмету. Количество таких вопросов в одном курсе может составлять сотни (у нас в курсе на два семестра "Профессиональная разработка вэб-приложений на python/django" тестовых входных, текущих и итоговых более 500 с картинками, кусками кода, сложными сценариями оценки и т.п.). Переиспользовать эти вопросы приходится в разных местах:
- в дистанционной системе;
- на бумажных распечатках (при оффлайн тестировании);
- в оргдокументах (ФОСах);
- ...
Акт "переиспользования" этих тестовых вопросов из примера осуществляется преподавателем путем "копипаста". В т.ч. при изменении вопросов (а это происходит нередко) приходится тратить внимание и время на синхронизацию. В нашей системе преподаватель ведет свою личную базу тестовых вопросов в удобном виде (ворд, markdown, LMS, ...). TRaC как и в случае со школьным расписанием "подхватывает" и публикует (не обязательно в открытом доступе) батареи тестовых вопросов в универсальном RDF-представлении. Из RDF-хранилища вопросы могут поступать в LMS (вообще любую с опубликованным форматом импорта), в вородовский формат для распечатки и т.п.
Все сказанное выше относится и к табличкам бухгалтеров, кадровиков, сметчиков, руководителей IT-проектов, "продажников", заведующих кафедрами и т.п.